
* 이 포스팅은 로드북 출판사의 백견불여일타 딥러닝 입문 with 텐서플로우 2.X 책을 바탕으로 제작되었습니다.
* 필자가 학습해서 얻었던 지식과 느낀 점 위주로 작성한 내용이고, 혹시 틀린 점이 있다면 댓글로 피드백 주시면 감사하겠습니다.
* 포스팅에 대한 문제가 있다면 댓글 남겨주시면 감사하겠습니다.
* 지난 시간에는 인공지능, 머신러닝, 딥러닝, 텐서플로우, 케라스의 개념 및 특징에 대해 학습하고 정리하는 시간을 가졌습니다.
이번 시간에는 머신러닝 프로세스, 데이터 준비 단계에 대해서 학습하고자 합니다.
머신러닝 프로세스
- 데이터를 다루면서 본인만의 프로세스를 구축하는 것은 매우 중요
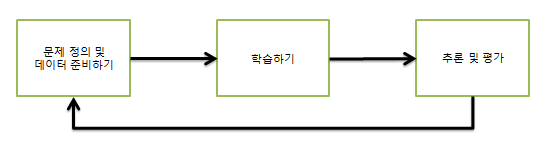
문제 정의 및 데이터 준비하기
탐색적 데이터 분석
- 데이터는 숫자? 문자? 이미지? 오디오? ...
- 해결방법(HOW?) 이진, 다중, 회귀, 생성?...
->문제 해결을 위한 형태로 데이터를 변형하는 데이터 전처리(Data Preprocessing) 방법 선택 중요
* 학습하기
- 모델 선택
- 선택 모델이 주로 어떤 데이터에 적용되었는가?
- 모델의 깊이, 환경
- 옵티마이저와 손실 함수?
- 우리의 실험 환경에 적합한가?
- 모델을 선택할 때, SOTA(state of the Art)를 달성한 모델로부터 시작
-> 여러 번의 실험을 통해 본인이 원하는 모델로 재구성, 또는 다른 모델 선택
- 선택 후, 하이퍼 파라미터(Hyper Parameter) 조정
- 배치 크기, 학습률, 드롭아웃률, 여러 가지 층이 가지는 파라미터 등의 요소를 변경해가면서 다양한 실험 진행
-> 여러 번 바꾸어 실험했다면, 그에 대한 기록을 해 둠.
* 추론 및 평가
- 케라스를 사용하면서 저장된 모델에서 하나 또는 몇 개의 함수 호출을 통해 추론 진행
- 추론(Inference) : 학습된 모델로부터 정답이 없는 데이터에 대해 정답을 만드는 행위
- 주어진 상황에 맞게 평가 기준을 세우고 최종 모델을 선택해야 함.
데이터 준비하기
* 클래스 불균형(Class Imbalance)
- 클래스가 불균형하게 분포되어 있는 것을 의미
- 이상 탐지(Aromaly Detection)
- 모델은 균형이 잡혀 있는 많고 다양한 클래스를 보는 것이 좋음
* 과소 표집(undo-sampling)
- 다른 클래스에 비해 상대적으로 많이 나타나고 있는 클래스의 개수를 줄이는 것
- 균형유지, 제거하는 과정에서 유용한 정보가 버려지게 되는 것이 단점
* 과대표 집(over-sampling)
- 데이터복제
- 무작위 or 기준 정의 복제
- 정보를 잃지 않기 때문에 학습용 데이터에서 높은 성능을 보이지만, 실험용 데이터에서의 성능은 낮아질 수 있음
* 과대적합의 문제를 피하기 위한 방법 : SMOTE(Synthetic Minority Over-Sampling Techinque)
- 데이터의 개수가 적은 클래스의 표본을 가져온 뒤 임의의 값을 추가하여 새로운 표본을 만들고 이를 데이터에 추가하는 것
* 회귀(Regression)
- 하나 또는 여러 개의 특징을 통해 연속적인 숫자로 이루어진 정답을 예측하는 것
- 독립변수 : 하나 또는 여러 개의 특징
- 종속변수 : 정답
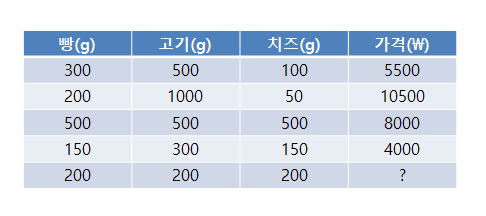
* 로지스틱 회귀(Logistic Regression) : 0과 1을 예측할 때 사용하는 회귀
* 분류(Classification)
- 데이터 셋에서 미리 정의된 여러 클래스 중 하나를 예측
- 정답 : 하나의 클래스에 속하는 것 (class, label, calss label)
- 이진 분류(Binary classification) : 두 개의 범주로 구분
- 다중 분류(Multi-class classification) : 세 개 이상의 범주로 구분
- 다중 레이블 분류(Multi-label classification) : 불고기버거, 치킨버거, 치즈버거, 콜라, 사이다, 환타가 있다면 불고기버거 세트를 택, 불고기버거와 콜라 레이블을 모두 할당
* 이진 분류의 예
- 햄버거를 선택한다면?
| 햄버거 | 음료 |
| 1 | 0 |
* 다중 분류의 예
- 불고기버거를 선택한다면?
| 불고기버거 | 치킨버거 | 치즈버거 |
| 1 | 0 | 0 |
* 불고기버거 세트를 선택했다면?
| 불고기버거 | 치킨버거 | 치즈버거 | 콜라 | 사이다 | 환타 |
| 1 | 0 | 0 | 1 | 0 | 0 |
* 원핫 인코딩(one - hot Encoding)
- 하나의 클래스만 1이고 나머지 클래스는 전부 0인 인코딩을 의미하고 자연어 처리 분야에서 많이 언급
- 불고기버거[1, 0, 0], 치킨버거[0, 1, 0], 치즈버거[0, 0, 1]
* 교차검증(cross - validation)
- 모델의 타당성을 검증하는 방법
- 데이터를 모두 사용하여 모델을 학습시킬 경우 해당 데이터는 매우 좋은 성능
- 새로운 데이터에 대해서는 좋은 성능을 보이지 못함
-> 대부분의 경우 모델이 과대 적합
- 학습 데이터(train_data) : 모델 학습에 사용
- 검증 데이터(validation_data) : 모델 검증, 주로 학습 도중에 사용
- 테스트 데이터(test-data) : 모델의 최종 성능 평가
- 검증 데이터를 만드는 이유 : 학습 도중 새로운 데이터에 대한 모델의 성능을 평가하기 위해 만듦
--> 테스트 데이터는 최종 평가 이전에는 절대로 사용 X -> 모델의 견고성
- 교차검증의 기법(Hold out, K-Fold)
<Hold out> : 데이터 셋을 무작위로 [학습, 테스트] or [학습, 검증, 테스트] 데이터로 나눔
| 학습 Data set | 검증 Data set | 테스트 Data set |
<학습 + 검증 + 테스트 = 데이터 전체 수>
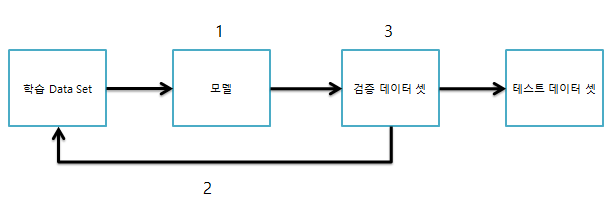
1. 모델을 학습
2. 검증을 통해 결과를 확인하고 학습을 다시 진행
3. 학습이 충분히 진행되었다면 최종 성능 확인
=> Hold out, 데이터를 분리하는 과정에서 최종 성능에 많은 영향
=> 과소 적합이 올 수 있음
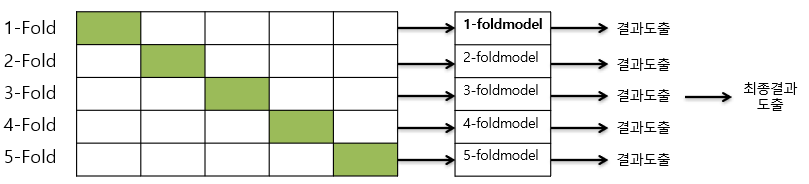
<K-Fold 교차 검증 기법>
- 데이터를 K개의 그룹으로 나눈 후에, 하나의 그룹을 제외하고 모든 그룹을 학습 데이터로 사용
- 이때, 제외할 하나의 그룹을 검증 데이터로써 사용됨. k는 주로 [3~10] 범위 값 사용
| 학습 데이터 셋 | 테스트 데이터 셋 |
<K - Fold 과정 1>
<색깔 O : 검증 Dats Set, 색깔 X : 학습 Data Set>
이번 시간에는 머신러닝 프로세스와 데이터 준비하는 과정에 대해 학습을 해보았습니다. 다음 시간에는 학습하는 부분을 학습해보도록 하겠습니다.
'Machine Learning' 카테고리의 다른 글
| [딥러닝] 딥러닝이란? 1 (0) | 2021.09.01 |
|---|---|
| [백견불여일타 딥러닝 입문 : 학습 5일차] (0) | 2021.01.30 |
| [백견불여일타 딥러닝 입문 : 학습 4일차] (0) | 2021.01.30 |
| [백견불여일타 딥러닝 입문 : 학습 3일차] (0) | 2021.01.30 |
| [백견불여일타 딥러닝 입문 : 학습 1일차] (0) | 2021.01.30 |