
* 이 포스팅은 로드북 출판사의 백견불여일타 딥러닝 입문 with 텐서플로우 2.X 책을 바탕으로 제작되었습니다.
* 필자가 학습해서 얻었던 지식과 느낀 점 위주로 작성한 내용이고, 혹시 틀린 점이 있다면 댓글로 피드백 주시면 감사하겠습니다.
* 포스팅에 대한 문제가 있다면 댓글 남겨주시면 감사하겠습니다.
지난 시간에는 머신러닝 프로세스와 데이터 준비하는 과정에 대해 학습을 해보았습니다. 이번 시간에는 학습, 평가하는 부분을 학습해보도록 하겠습니다.
* 학습하기(용어설명)
- 하이퍼 파라미터(HyperParameter)
: 어떠한 값이 적절한 지 모델과 데이터가 알려주지 않기 때문에 모델 외적인 요소라고 표현하기도 하는데, 주로 경험에 의해 결정되는 요소를 의미
: 학습률, 배치크기(betch size), 에폭(epochs), 드롭아웃률 등이 있음.
: 최적의 값을 찾기 위해 다양한 값을 시도해보면서 반복적인 실험과 많은 시간을 투자 -> 하이퍼 파라미터 튜닝(그리드 서치, 랜덤 서치)
- 배치와 배치 크기
: 배치 학습 : 메모리와 속도 측면에서 많은 이득
: 100개의 데이터, 배치 = 10, 배치 당 100개의 데이터
- 에폭과 스텝
: 에폭(epochs) : 전체 데이터를 사용하여 학습하는 횟수 의미
-> 전체 데이터를 10회 반복하여 모델을 학습시킨 것 ->10 에폭
: 스텝(steps) : 모델이 가진 파라미터(또는 가중치)를 1회 업데이트하는 것을 의미
: 전체 데이터 1000개, 배치 크기 10,
10 에폭 = 1000 * 10번 사용 -> 스텝으로 변환, 1000 스텝
스텝 = 배치 크기 / 전체 데이터 사용 수
- 지도 학습(Supervised Learning)
: 학습 데이터에 정답이 포함되는 것을 의미
: 회귀, 분류가 이에 해당
- 비지도 학습
: 학습 데이터에 정답이 포함되어 있지 않은 것을 의미
: 생성 모델 : 햄버거 사진을 주고, 다시 모델에게 햄버거 사진을 그려보라고 하는 것.
- 과대 적합(Overfitting)
: 모델이 학습 데이터에서는 좋은 성능을 보이지만 새로운 데이터에 대해서는 좋은 성능을 보이지 못하는 결과 의미
: 학습 데이터를 단순 암기, 모델이 문제를 일반화하지 못한 상태
<해결방법>
- 학습 데이터를 다양하게 많이 수집
- 정규화 사용 -> 규칙 단순화
- 이상치(outlier) 제거
- 과소 적합(Underfitting)
: 학습 데이터를 충분히 학습하지 않아 모든 측면에서 성능이 나쁨
<해결방법>
- 학습 데이터를 다양하게 많이 수집
- 더 복잡한 모델 사용
- 모델을 충분히 학습
-> 양질의 데이터 수집
* 평가하기
- 혼동 행렬(confusion Matrix)
: 알고리즘이나 모델의 성능을 평가할 때 많이 사용.
|
|
예측된 정답 |
||
|
True |
False |
||
|
실제 정답 |
True |
TP |
FN |
|
False |
FP |
TN |
|
<정상 햄버거와 유통기한이 지난 햄버 분류의 예>
- 유통기한이 지난 햄버거를 유통기한이 지난 햄버거로 분류한 경우 : TP(Ture Positive)
- 정상 햄버거를 정상 햄버거로 분류한 경우 : TN(True Negative)
- 유통기한이 지난 햄버거를 정상 햄버거로 잘못 분류한 경우 : FN(False Negative)
- 정상 햄버거를 유통기한이 지난 햄버거로 잘못 분류한 경우 : FP(False positive)
- 정확도(Accuracy) : 전체 데이터 중에서 실제 데이터의 정답과 모델이 예측한 정답이 같은 비율로 나타냄.
ACC = (TP + TN) / (TP + TN + FP + FN)
- 정밀도(Precision)
: 모델이 True라고 예측한 정답 중에서, 실제로 True인 비율
정밀도 = TP / (TP + FP)
- 재현율(Recall)
: 실제 데이터가 True 인 것 중에서 모델이 True라고 예측한 비율
재현율 = TP / (TP + FN)
* 두 지표의 관계 : 트레이드오프(Trade Off) -> 정밀도를 올리면 재현율이 내려가고, 재현율이 올라가면 정밀도가 내려감
- F1-스코어 : 정밀도와 재현율의 임계치를 잘못 설정해서 극단적으로 가는 경우 방지
F1 = 2 * (Precision * Recall) / Precision + Recall
* ROC곡선
- 특이도(Specificity) : 모델이 False라고 예측한 정답 중 실제로 정답이 False인 비율
Specificity = TN / (FP + TN)
- 진짜 양성 비율(TPR, True Positive Rate) = 민감도
- 가짜 양성 비율(FPR, False Positive Rate) : 실제로 False이지만 True로 잘못 예측한 비율을 의미 (1 - 특이도)
- ROC 곡선 : 진짜 양성비율(TPR)과 가짜 양성비율(FPR) 두 가지 지표의 변화를 보기 위해 그래프로 나타낸 것
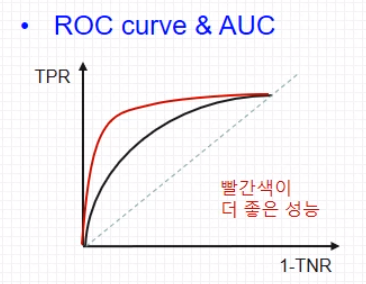
- AUC(Area Under the Curve) : 곡선 아래의 면적 , AUC의 면적이 넓을수록 좋은 성능을 보인다.
이번 시간에는 모델을 학습하고, 평가 부분에서 다루는 용어와 개념을 학습해보았습니다. 다음 시간에는 텐서를 통한 표현을 학습해보겠습니다.
참고 블로그 : nittaku.tistory.com/297
15. ROC(Receiver Operating Characteristic) curve 와 AUC(Area Under the Curve)
그림 및 글작성에 대한 도움 출저 : 유튜브 - 테리 엄태웅님의 딥러닝 토크 개요 딥러닝에 있어서, Accuracy말고도 여러가지 metric을 보아야하는 것 중 하나가 ROC커브이다. 저번시간에 다룬 아래의 4
nittaku.tistory.com
'Machine Learning' 카테고리의 다른 글
| [딥러닝] 딥러닝이란? 1 (0) | 2021.09.01 |
|---|---|
| [백견불여일타 딥러닝 입문 : 학습 5일차] (0) | 2021.01.30 |
| [백견불여일타 딥러닝 입문 : 학습 4일차] (0) | 2021.01.30 |
| [백견불여일타 딥러닝 입문 : 학습 2일차] (0) | 2021.01.30 |
| [백견불여일타 딥러닝 입문 : 학습 1일차] (0) | 2021.01.30 |
* 이 포스팅은 로드북 출판사의 백견불여일타 딥러닝 입문 with 텐서플로우 2.X 책을 바탕으로 제작되었습니다.
* 필자가 학습해서 얻었던 지식과 느낀 점 위주로 작성한 내용이고, 혹시 틀린 점이 있다면 댓글로 피드백 주시면 감사하겠습니다.
* 포스팅에 대한 문제가 있다면 댓글 남겨주시면 감사하겠습니다.
지난 시간에는 머신러닝 프로세스와 데이터 준비하는 과정에 대해 학습을 해보았습니다. 이번 시간에는 학습, 평가하는 부분을 학습해보도록 하겠습니다.
* 학습하기(용어설명)
- 하이퍼 파라미터(HyperParameter)
: 어떠한 값이 적절한 지 모델과 데이터가 알려주지 않기 때문에 모델 외적인 요소라고 표현하기도 하는데, 주로 경험에 의해 결정되는 요소를 의미
: 학습률, 배치크기(betch size), 에폭(epochs), 드롭아웃률 등이 있음.
: 최적의 값을 찾기 위해 다양한 값을 시도해보면서 반복적인 실험과 많은 시간을 투자 -> 하이퍼 파라미터 튜닝(그리드 서치, 랜덤 서치)
- 배치와 배치 크기
: 배치 학습 : 메모리와 속도 측면에서 많은 이득
: 100개의 데이터, 배치 = 10, 배치 당 100개의 데이터
- 에폭과 스텝
: 에폭(epochs) : 전체 데이터를 사용하여 학습하는 횟수 의미
-> 전체 데이터를 10회 반복하여 모델을 학습시킨 것 ->10 에폭
: 스텝(steps) : 모델이 가진 파라미터(또는 가중치)를 1회 업데이트하는 것을 의미
: 전체 데이터 1000개, 배치 크기 10,
10 에폭 = 1000 * 10번 사용 -> 스텝으로 변환, 1000 스텝
스텝 = 배치 크기 / 전체 데이터 사용 수
- 지도 학습(Supervised Learning)
: 학습 데이터에 정답이 포함되는 것을 의미
: 회귀, 분류가 이에 해당
- 비지도 학습
: 학습 데이터에 정답이 포함되어 있지 않은 것을 의미
: 생성 모델 : 햄버거 사진을 주고, 다시 모델에게 햄버거 사진을 그려보라고 하는 것.
- 과대 적합(Overfitting)
: 모델이 학습 데이터에서는 좋은 성능을 보이지만 새로운 데이터에 대해서는 좋은 성능을 보이지 못하는 결과 의미
: 학습 데이터를 단순 암기, 모델이 문제를 일반화하지 못한 상태
<해결방법>
- 학습 데이터를 다양하게 많이 수집
- 정규화 사용 -> 규칙 단순화
- 이상치(outlier) 제거
- 과소 적합(Underfitting)
: 학습 데이터를 충분히 학습하지 않아 모든 측면에서 성능이 나쁨
<해결방법>
- 학습 데이터를 다양하게 많이 수집
- 더 복잡한 모델 사용
- 모델을 충분히 학습
-> 양질의 데이터 수집
* 평가하기
- 혼동 행렬(confusion Matrix)
: 알고리즘이나 모델의 성능을 평가할 때 많이 사용.
|
|
예측된 정답 |
||
|
True |
False |
||
|
실제 정답 |
True |
TP |
FN |
|
False |
FP |
TN |
|
<정상 햄버거와 유통기한이 지난 햄버 분류의 예>
- 유통기한이 지난 햄버거를 유통기한이 지난 햄버거로 분류한 경우 : TP(Ture Positive)
- 정상 햄버거를 정상 햄버거로 분류한 경우 : TN(True Negative)
- 유통기한이 지난 햄버거를 정상 햄버거로 잘못 분류한 경우 : FN(False Negative)
- 정상 햄버거를 유통기한이 지난 햄버거로 잘못 분류한 경우 : FP(False positive)
- 정확도(Accuracy) : 전체 데이터 중에서 실제 데이터의 정답과 모델이 예측한 정답이 같은 비율로 나타냄.
ACC = (TP + TN) / (TP + TN + FP + FN)
- 정밀도(Precision)
: 모델이 True라고 예측한 정답 중에서, 실제로 True인 비율
정밀도 = TP / (TP + FP)
- 재현율(Recall)
: 실제 데이터가 True 인 것 중에서 모델이 True라고 예측한 비율
재현율 = TP / (TP + FN)
* 두 지표의 관계 : 트레이드오프(Trade Off) -> 정밀도를 올리면 재현율이 내려가고, 재현율이 올라가면 정밀도가 내려감
- F1-스코어 : 정밀도와 재현율의 임계치를 잘못 설정해서 극단적으로 가는 경우 방지
F1 = 2 * (Precision * Recall) / Precision + Recall
* ROC곡선
- 특이도(Specificity) : 모델이 False라고 예측한 정답 중 실제로 정답이 False인 비율
Specificity = TN / (FP + TN)
- 진짜 양성 비율(TPR, True Positive Rate) = 민감도
- 가짜 양성 비율(FPR, False Positive Rate) : 실제로 False이지만 True로 잘못 예측한 비율을 의미 (1 - 특이도)
- ROC 곡선 : 진짜 양성비율(TPR)과 가짜 양성비율(FPR) 두 가지 지표의 변화를 보기 위해 그래프로 나타낸 것
- AUC(Area Under the Curve) : 곡선 아래의 면적 , AUC의 면적이 넓을수록 좋은 성능을 보인다.
이번 시간에는 모델을 학습하고, 평가 부분에서 다루는 용어와 개념을 학습해보았습니다. 다음 시간에는 텐서를 통한 표현을 학습해보겠습니다.
참고 블로그 : nittaku.tistory.com/297
15. ROC(Receiver Operating Characteristic) curve 와 AUC(Area Under the Curve)
그림 및 글작성에 대한 도움 출저 : 유튜브 - 테리 엄태웅님의 딥러닝 토크 개요 딥러닝에 있어서, Accuracy말고도 여러가지 metric을 보아야하는 것 중 하나가 ROC커브이다. 저번시간에 다룬 아래의 4
nittaku.tistory.com
'Machine Learning' 카테고리의 다른 글
| [딥러닝] 딥러닝이란? 1 (0) | 2021.09.01 |
|---|---|
| [백견불여일타 딥러닝 입문 : 학습 5일차] (0) | 2021.01.30 |
| [백견불여일타 딥러닝 입문 : 학습 4일차] (0) | 2021.01.30 |
| [백견불여일타 딥러닝 입문 : 학습 2일차] (0) | 2021.01.30 |
| [백견불여일타 딥러닝 입문 : 학습 1일차] (0) | 2021.01.30 |